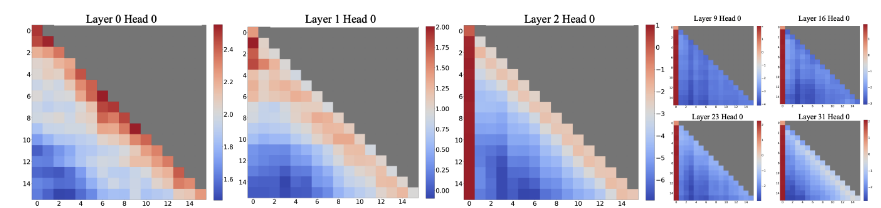
In many large language models (e.g., GPT, LLaMA, etc.):
- The first token or BOS (beginning-of-sequence) token receives disproportionately high attention across many heads.
- Other tokens frequently point part of their attention to it, regardless of content.
- This “sink token” acts like a gravitational center for attention flow.
Example:
When generating a sentence like
“The cat sat on the mat.”
some heads give large attention weights to the BOS token instead of semantically related tokens like “cat” or “mat.”
Few possible explanations:
- Softmax constraint: attention weights must sum to 1, so some residual mass tends to concentrate on a “default” token.
- Key–query alignment bias: the sink token’s key vector aligns strongly with many query vectors, leading to high dot-products.
- Training reinforcement: once a token attracts attention early in training, gradients reinforce the bias (a self-fulfilling “rich-get-richer” effect).
- Architectural bias: positional or initialization choices make the first token easier to attend to.
It has major impacts:
- In streaming inference (e.g., StreamingLLM), removing old tokens can harm performance if the sink token is evicted - so some systems keep it in memory.
- In interpretability, many “sink heads” produce little useful output; identifying them helps prune redundant computation.
- In memory optimization, only keeping sink KVs + recent tokens can reduce GPU KV-cache footprint.