Wave quantization is the idle tail you get when the number of GEMM tiles is not divisible by the number of SMs. CUDA executes blocks in waves; any partially filled wave tanks efficiency because the remaining SMs sit idle.
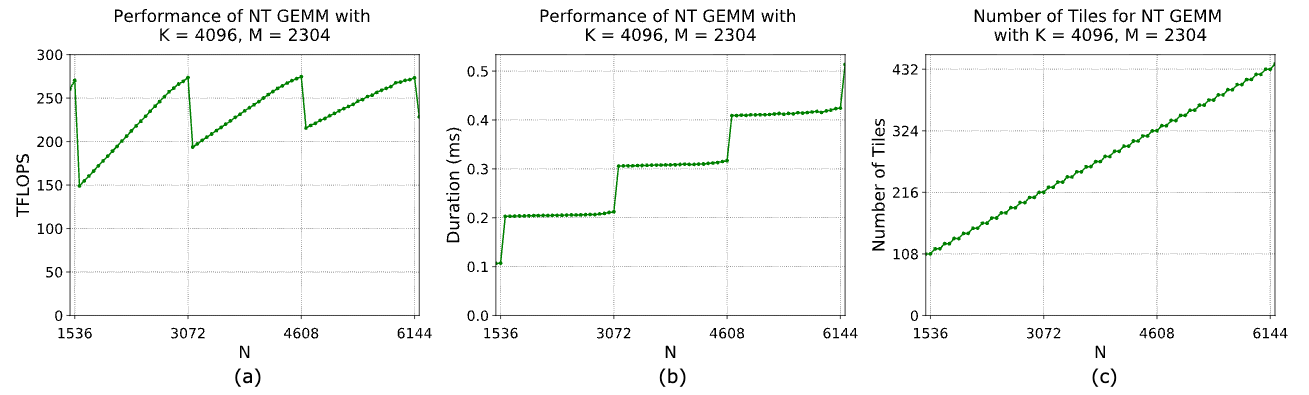
1. Performance (TFLOPs) oscillates in a saw-tooth pattern As N increases, TFLOPs rise smoothly, then suddenly drop at specific N values. Those drops happen exactly when the tile count crosses a multiple of SM count → a new wave begins, but the first wave of that new region is nearly empty.
2. Kernel duration steps upward instead of growing smoothly Duration vs. N is not linear. It increases in plateaus, then jumps sharply. Each jump corresponds to requiring one extra wave. Even if the extra wave contains only a few blocks, the cost of a wave is dominated by its slowest (or only) block.
3. Tile count grows linearly with N, but waves grow discretely The tile count plot is just a line. But every time it crosses a multiple of SM_count, the scheduler must add another wave. That mismatch - linear tiles vs. discrete waves - is the root cause of the performance oscillations.
Minimal synthesis
- Performance spikes upward as waves become fuller.
- Performance drops when you start a new wave that is mostly empty.
- Runtime increases abruptly at those same points because a new, under-filled wave must run to completion.
- These artifacts have nothing to do with memory throughput or compute intensity - they are purely a tiling × SM-count divisibility effect.
In conclusion, wave quantization produces predictable cliffs in GEMM performance:
- Smooth gains while filling a wave, sharp losses whenever a new (empty) wave is created.
- Your GEMM efficiency is literally periodic in N, controlled by tile geometry and SM count.