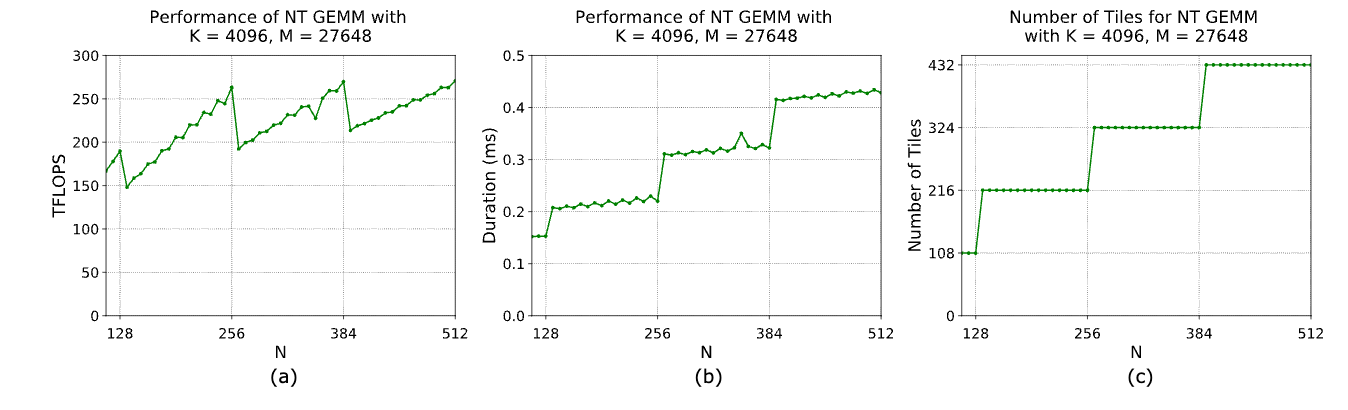
Tile quantization = how full each thread block (tile) is. If your matrix dimension is a clean multiple of the block size (e.g., 64), every tile is fully utilized → great throughput.
But when dimensions aren’t multiples of the tile size, CUDA still launches the same number of thread blocks, except now many tiles are partially empty. Runtime stays roughly the same (same #blocks fired), but the % of useful work drops.
The result: Lower arithmetic utilization → visible drops in TFLOPs, even though compute time doesn’t change. The “performance cliff” you see at sizes like 257, 385, etc., is exactly this tile under-utilization.
In short: performance dips not because kernels slow down, but because you’re doing the same work with fewer useful ops per tile.