def drop_out_matrices(layers_dims, m, keep_prob):
"""
Initializes the dropout matrices that will be used in both forward prop
and back-prop on each layer. We'll use random numbers from uniform
distribution.
Arguments
---------
layers_dims : list
input size and size of each layer, length: number of layers + 1.
m : int
number of training examples.
keep_prob : list
probabilities of keeping a neuron (unit) active for each layer on each
iteration.
Returns
-------
D : dict
dropout matrices for each layer l. Each dropout matrix on each layer
would have the same dimension as post activation output matrix "A".
For example: "D1" shape: number of units x number of examples.
"""
np.random.seed(1)
D = {}
L = len(layers_dims)
for l in range(L):
# initialize the random values for the dropout matrix
D[str(l)] = np.random.rand(layers_dims[l], m)
# Convert it to 0/1 to shut down neurons corresponding to each element
D[str(l)] = D[str(l)] < keep_prob[l]
assert D[str(l)].shape == (layers_dims[l], m)
return D
def L_model_forward(X, parameters, D, keep_prob, hidden_layers_activation_fn="relu"):
"""
Computes the output layer through looping over all units in topological
order.
X : 2d-array
input matrix of shape input_size x training_examples.
parameters : dict
contains all the weight matrices and bias vectors for all layers.
D : dict
dropout matrices for each layer l.
keep_prob : list
probabilities of keeping a neuron (unit) active for each layer on each
iteration.
hidden_layers_activation_fn : str
activation function to be used on hidden layers: "tanh","relu".
Returns
-------
AL : 2d-array
probability vector of shape 1 x training_examples.
caches : list
that contains L tuples where each layer has: A_prev, W, b, Z.
"""
A = X # since input matrix A0
A = np.multiply(A, D[str(0)])
A /= keep_prob[0]
caches = [] # initialize the caches list
L = len(parameters) // 2 # number of layer in the network
for l in range(1, L):
A_prev = A
A, cache = linear_activation_forward(
A_prev,
parameters["W" + str(l)],
parameters["b" + str(l)],
hidden_layers_activation_fn,
)
# shut down some units
A = np.multiply(A, D[str(l)])
# scale that value of units to keep expected value the same
A /= keep_prob[l]
caches.append(cache)
AL, cache = linear_activation_forward(
A, parameters["W" + str(L)], parameters["b" + str(L)], "sigmoid"
)
AL = np.multiply(AL, D[str(L)])
AL /= keep_prob[L]
caches.append(cache)
assert AL.shape == (1, X.shape[1])
return AL, caches
def L_model_backward(AL, Y, caches, D, keep_prob, hidden_layers_activation_fn="relu"):
"""
Computes the gradient of output layer w.r.t weights, biases, etc. starting
on the output layer in reverse topological order.
Arguments
---------
AL : 2d-array
probability vector, output of the forward propagation
(L_model_forward()).
y : 2d-array
true "label" vector (containing 0 if non-cat, 1 if cat).
caches : list
list of caches for all layers.
D : dict
dropout matrices for each layer l.
keep_prob : list
probabilities of keeping a neuron (unit) active for each layer on each
iteration.
hidden_layers_activation_fn :
activation function used on hidden layers: "tanh", "relu".
Returns
-------
grads : dict
gradients.
"""
Y = Y.reshape(AL.shape)
L = len(caches)
grads = {}
# dA for output layer
dAL = np.divide(AL - Y, np.multiply(AL, 1 - AL))
dAL = np.multiply(dAL, D[str(L)])
dAL /= keep_prob[L]
(
grads["dA" + str(L - 1)],
grads["dW" + str(L)],
grads["db" + str(L)],
) = linear_activation_backward(dAL, caches[L - 1], "sigmoid")
grads["dA" + str(L - 1)] = np.multiply(grads["dA" + str(L - 1)], D[str(L - 1)])
grads["dA" + str(L - 1)] /= keep_prob[L - 1]
for l in range(L - 1, 0, -1):
current_cache = caches[l - 1]
(
grads["dA" + str(l - 1)],
grads["dW" + str(l)],
grads["db" + str(l)],
) = linear_activation_backward(
grads["dA" + str(l)], current_cache, hidden_layers_activation_fn
)
grads["dA" + str(l - 1)] = np.multiply(grads["dA" + str(l - 1)], D[str(l - 1)])
grads["dA" + str(l - 1)] /= keep_prob[l - 1]
return grads
def model_with_dropout(
X,
Y,
layers_dims,
keep_prob,
learning_rate=0.01,
num_iterations=3000,
print_cost=True,
hidden_layers_activation_fn="relu",
):
"""
Implements multilayer neural network with dropout using gradient descent as the
learning algorithm.
Arguments
---------
X : 2d-array
data, shape: number of examples x num_px * num_px * 3.
y : 2d-array
true "label" vector, shape: 1 x number of examples.
layers_dims : list
input size and size of each layer, length: number of layers + 1.
keep_prob : list
probabilities of keeping a neuron (unit) active for each layer on each
iteration.
learning_rate : float
learning rate of the gradient descent update rule.
num_iterations : int
number of iterations of the optimization loop.
print_cost : bool
if True, it prints the cost every 100 steps.
hidden_layers_activation_fn : str
activation function to be used on hidden layers: "tanh", "relu".
Returns
-------
parameters : dict
parameters learnt by the model. They can then be used to predict test
examples.
"""
# get number of examples
m = X.shape[1]
# to get consistents output
np.random.seed(1)
# initialize parameters
parameters = initialize_parameters(layers_dims)
# intialize cost list
cost_list = []
# implement gradient descent
for i in range(num_iterations):
# Initialize dropout matrices
D = drop_out_matrices(layers_dims, m, keep_prob)
# compute forward propagation
AL, caches = L_model_forward(
X, parameters, D, keep_prob, hidden_layers_activation_fn
)
# compute regularized cost
cost = compute_cost(AL, Y)
# compute gradients
grads = L_model_backward(
AL, Y, caches, D, keep_prob, hidden_layers_activation_fn
)
# update parameters
parameters = update_parameters(parameters, grads, learning_rate)
# print cost
if (i + 1) % 100 == 0 and print_cost:
print(f"The cost after {i + 1} iterations : {cost:.4f}.")
# append cost
if i % 100 == 0:
cost_list.append(cost)
# plot the cost curve
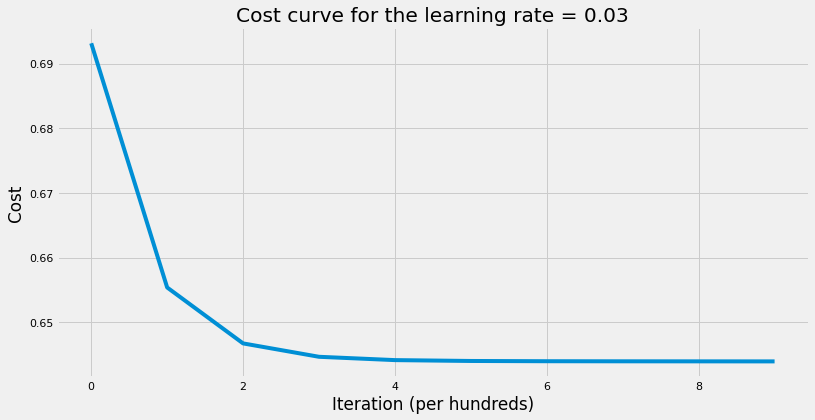
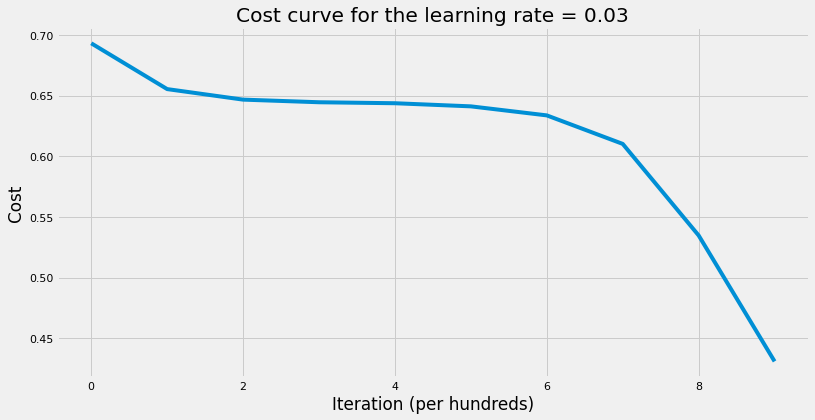
plt.plot(cost_list)
plt.xlabel("Iteration (per hundreds)")
plt.ylabel("Cost")
plt.title(f"Cost curve for the learning rate = {learning_rate}")
return parameters