
Other than my experience and the documentation, the main resource behind this post and figures is the fantastic book: Data Pipelines with Apache. Airflow.
Airflow is workflow orchestration tool that is written in Python at Airbnb. The workflow is also written in Python. It defines the workflow as a DAG so it is easy to determine the dependencies between tasks. If any task failed, we don’t need to rerun the workflow again, we can just run the failed task and all the tasks that depend on it. We can also do backfilling by running the pipeline/tasks for time intervals in the past.
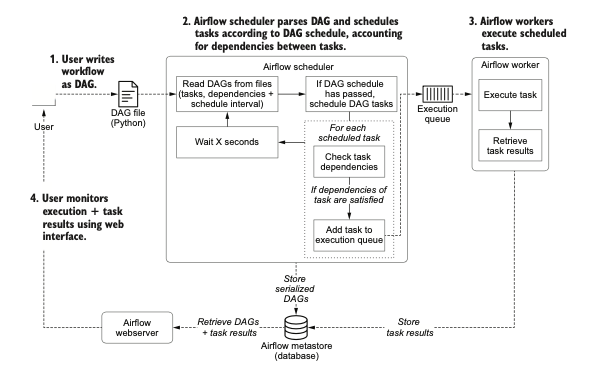
Airflow consists of mainly three components:
- The Airflow scheduler: Parses DAGs, checks their schedule interval, and (if the DAGs’ schedule has passed) starts scheduling the DAGs’ tasks for execution by passing them to the Airflow workers.
- The Airflow workers: Pick up tasks that are scheduled for execution and execute them. As such, the workers are responsible for actually “doing the work.”
- The Airflow webserver: Visualizes the DAGs parsed by the scheduler and provides the main interface for users to monitor DAG runs and their results. It uses the metadata database which has all the logs and other metadata about tasks and workflows.
Conceptually, the scheduling algorithm follows the following steps:
- For each open (= uncompleted) task in the graph, do the following: – For each edge pointing toward the task, check if the “upstream” task on the other end of the edge has been completed. – If all upstream tasks have been completed, add the task under consideration to a queue of tasks to be executed.
- Execute the tasks in the execution queue, marking them completed once they finish performing their work.
- Jump back to step 1 and repeat until all tasks in the graph have been completed.
The scheduler in Airflow runs roughly through the following steps:
- Once users have written their workflows as DAGs, the files containing these DAGs are read by the scheduler to extract the corresponding tasks, dependen- cies, and schedule interval of each DAG.
- For each DAG, the scheduler then checks whether the schedule interval for the DAG has passed since the last time it was read. If so, the tasks in the DAG are scheduled for execution.
- For each scheduled task, the scheduler then checks whether the dependencies (= upstream tasks) of the task have been completed. If so, the task is added to the execution queue.
- The scheduler waits for several moments before starting a new loop by jumping back to step 1.
Airflow can be run:
- In python virtual environment
- Inside Docker containers. In this case, Airflow scheduler, webserver, and metastore would run each in separate containers
The main disadvantages of Airflow are:
- It can get very messy and hard to understand for complex workflows
- It is best used for batch/recurring jobs NOT streaming jobs
- Mainly support static DAGs and hard to implement dynamic DAGs. Imagine you’re reading from a database and you want to create a step to process each record in the database (e.g. to make a prediction), but you don’t know in advance how many records there are in the database, Airflow won’t be able to handle that.
- It is monolithic, which means it packages the entire workflow into one container. If two different steps in your workflow have different requirements, you can, in theory, create different containers for them using Airflow’s DockerOperator, but it’s not that easy to do so.
- Airflow’s DAGs are not parameterized, which means you can’t pass parameters into your workflows. So if you want to run the same model with different learning rates, you’ll have to create different workflows.
To setup Airflow locally inside Python virtual env:
- pip install apache-airflow
- airflow init db # Initialize metastore locally using SQLite; not recommended for production
- airflow users create –username admin –password admin –firstname Anonymous –lastname Admin –role Admin –email admin@example.org # Create user
- airflow webserver # Start web server to use web UI
- airflow scheduler # Start scheduler, don’t use sequential in production